今、明天兩天打算來寫寫Python的程式碼補充。
今天預計補充「資料前處理、遺失值處理、探索式資料分析」的部分,明天則是「線性迴歸、正規化迴歸、變數篩選」的程式碼補充。補充完 Python 的程式碼後,將要進入到「分群」的機器學習模型part!
常見import慣例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels as sm
其他 import :
## Common imports
import sys
import sklearn #機器學習常用套件
import os
## plot作圖
import matplotlib as mpl
import matplotlib.pyplot as plt
## 讀取資料
## 1.直接從自己電腦上的位置
data=pd.read_csv(r'C:\Users\User\Desktop\data.csv')
data=pd.read_csv(csv_path, names=['col_a','col_b']) # names更改columns names
data=pd.read_csv(csv_path,header=None) # 不載入 column_name
## 2.從網站url
url = 'https://raw.githubusercontent.com/.../Python_dataset/data.csv' #請自行更改網站
data = pd.read_csv(url,sep=",") # sep="," for coma separation.
## 輸出資料
df.to_csv('df.csv')
None(空格)、np.nan代表為遺失值,其中pandas pd.isnull()回傳NaN (not a number)代表遺失值。import nan as NA 時,NA 可以被當成| 指令用處 | Python Code |
|---|---|
| 是否為遺失值 | df.isnull( ) , pd.isnull(df) ,回傳 True 時代表有遺失值NA |
| 各欄位(col.變數)的遺失值個數 | df.isnull( ).sum( ) |
| 移除遺失值(移除該row) | df.dropna( ), df.dropna(subset=['col_names']) |
| 遺失值填補0 | df.fillna(0) |
| 遺失值填補平均 | df.fillna(df.mean( )) |
| 特定欄位填補平均 | df['col_name'].fillna(mean, inplace=True) |
| 刪除欄位 | df.dropna('col_names', axis=1) |
| 取代值 | df.replace(to_replace, replace_value) |
| 排序 | df.sort_values(by='col_name') |
| 分組 | groupby( ) |
## NaN_df
df = pd.DataFrame([['a','b',np.nan,'d'],['a1','b2','c3','d4'],['aa','bb','cc',]])# 4col變數欄位,3筆資料
df.isnull()
pd.isnull(df)
df = pd.DataFrame([[1,4,np.nan,9],[1,10,],['aa','bb','cc',]])# 4col變數欄位,3筆資料
df.fillna(0) # 填補0
df.fillna(df.mean()) # 填補平均
## 取代值 df.replace([to_replace_list], replace_value)
df = pd.DataFrame({'col_1':['a','b','c','d','e','f','g','h'],
'col_2':[8,-1,4,9,0,4,9,0],
'col_3':[-8,0,7,2,2,5,0,3]}) # 3 col, 8rows
df.replace(['a','b'],'new_a')
df.replace([0,2],-99) # 取代值
df.replace([0,2],'new_a')
## 排序
df.sort_values(by='col_3')
df.sort_values(by=['col_3','col_2'])
## groupby() ## num. + charc. df
df = pd.DataFrame({'col_1':['a','b','c','d','e','f','g','h'],
'col_2':[8,-1,4,9,0,4,9,0],
'col_3':[-8,0,7,2,2,5,0,3]}) # 3 col, 8 rows
gp=df['col_3'].groupby(df['col_4']) #col3的數值,以col4分組
gp.mean() #各col4分組的col3數值平均
NaN值會被忽略)| 指令用處 | Python Code |
|---|---|
| 前n筆資料 | df.head(n) |
| 各欄位狀態 | df.info( ) |
| 各數值(numeric)欄位統計值 | df.describe( ) |
| 各col.欄位的非NA數,各欄位的資料數 | df.count( ) |
| 平均 | df.mean( ) |
| 變異數 | df.var( ) |
| 偏態 | df.skew( ) |
| 峰態 | df.kurt( ) |
| 相關係數矩陣 | df.corr( ) |
| 共變異數矩陣 | df.cov( ) |
接下來會以 California Housing price 的資料作為示範。
我們可以直接從 sklearn.datasets 套件上獲取資料,來源網址及詳細資料。
資料讀取:
from sklearn.datasets import fetch_california_housing
housing_df = fetch_california_housing(as_frame=True).frame
housing_y = fetch_california_housing(as_frame=True).target
housing_x=fetch_california_housing(as_frame=True).data
## 觀察資料
housing_df.describe() # summary numerical attribute
housing_df.head(4) # 前4筆資料
housing_df.info() # information
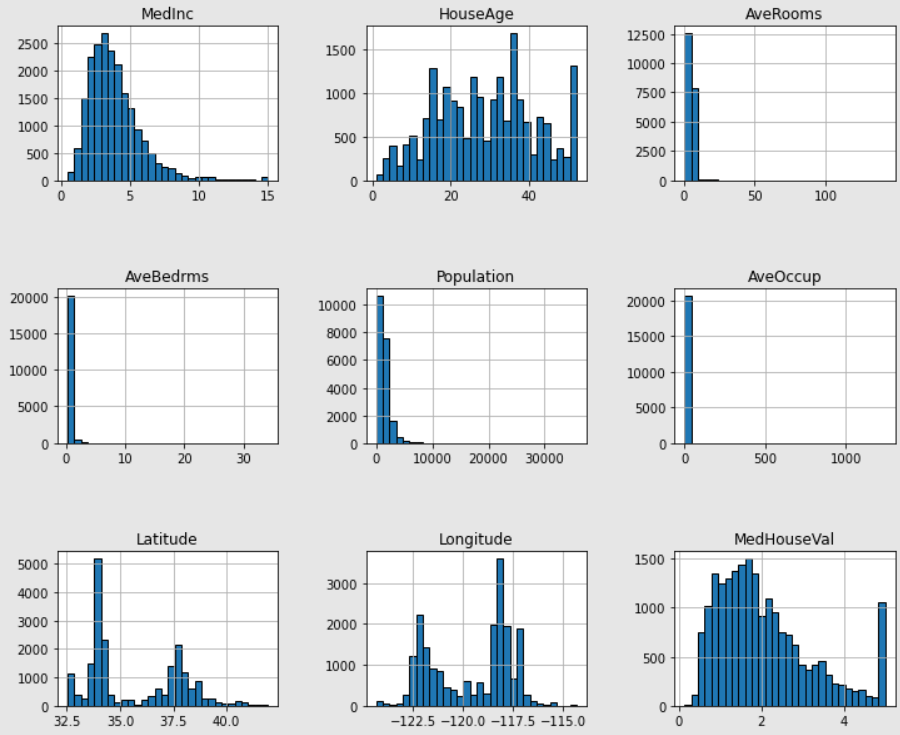
df.hist()
import matplotlib.pyplot as plt # plot作圖
housing_df.hist(figsize=(12, 10), bins=30, edgecolor="black")
plt.subplots_adjust(hspace=0.7, wspace=0.4)
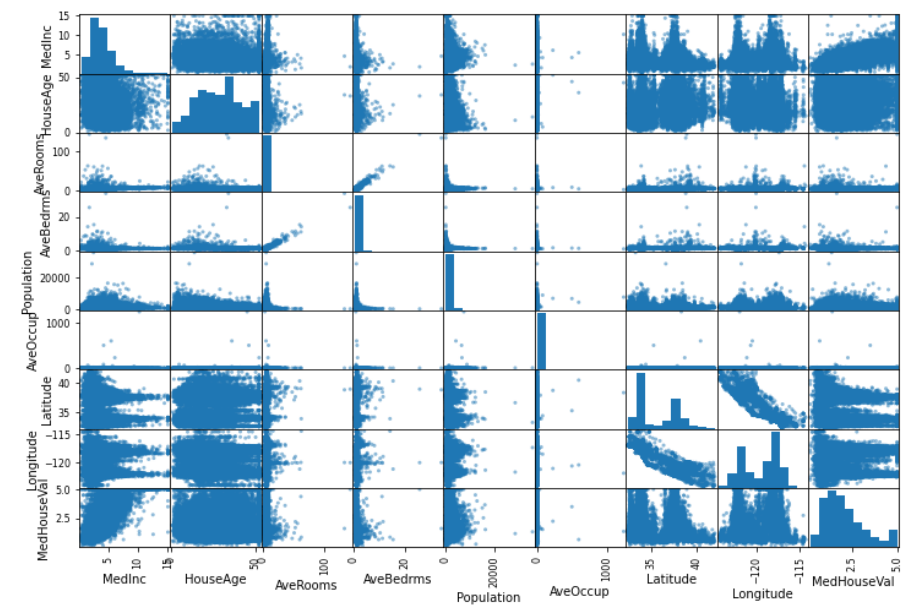
from pandas.plotting import scatter_matrix
scatter_matrix(housing_df, figsize=(12,8))
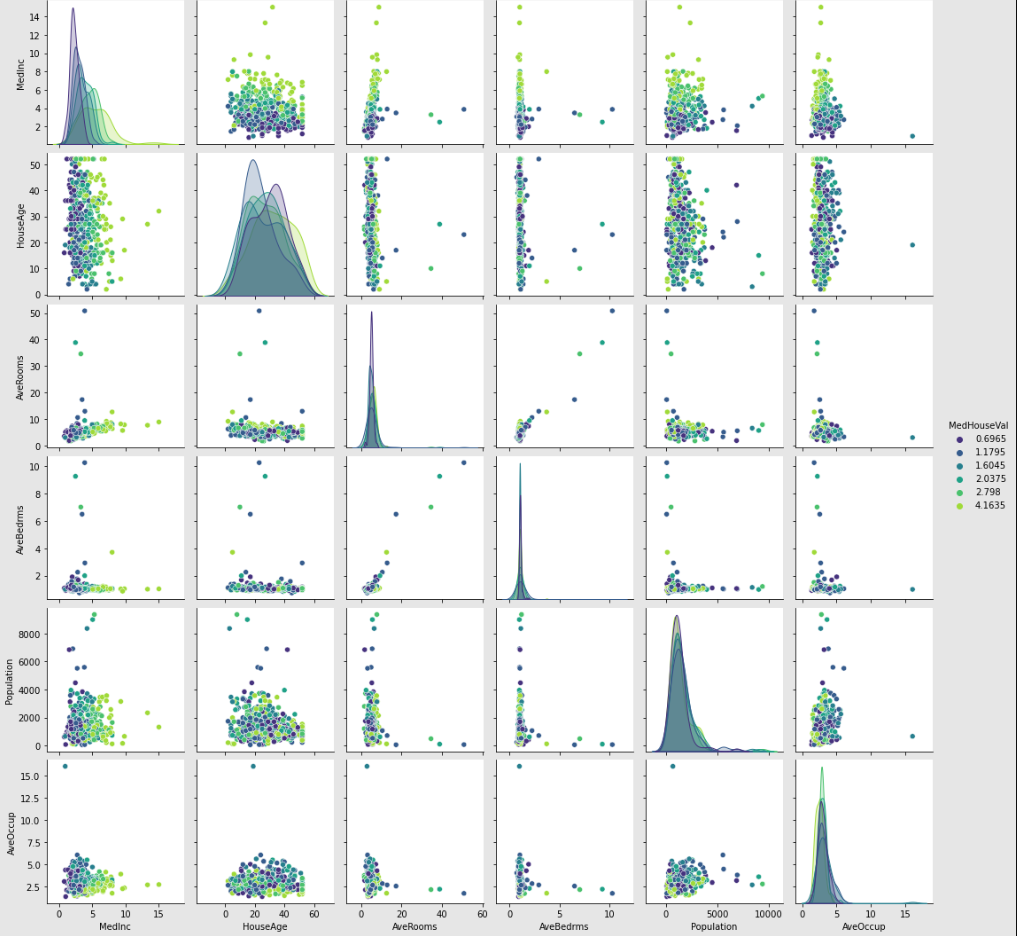
import pandas as pd
import numpy as np
import seaborn as sns
#資料原始有20640筆,太多了,所以再仍看得出趨勢的情況下抽樣,以樣本點展示
rng = np.random.RandomState(0)
indices = rng.choice(np.arange(housing_df.shape[0]), size=500,
replace=False)
# Drop the unwanted columns 探討解釋變數們與目標(房價中位數)的關係時,不打算用到經度、緯度這兩個變數
columns_drop = ["Longitude", "Latitude"]
subset = housing_df.iloc[indices].drop(columns=columns_drop) # 刪除經度、緯度.欄位
# 以我們有興趣的目標變數(MedHouseVal:median house value)來做顏色分區,共分6區
subset["MedHouseVal"] = pd.qcut(subset["MedHouseVal"], 6, retbins=False)
subset["MedHouseVal"] = subset["MedHouseVal"].apply(lambda x: x.mid)
## pairs plot
_ = sns.pairplot(data=subset, hue="MedHouseVal", palette="viridis")
scikit-learn course
https://inria.github.io/scikit-learn-mooc/python_scripts/datasets_california_housing.html

